
文獻標識碼: A
文章編號: 0258-7998(2011)12-0126-04
近年來隨著各種應用計算需求的不斷增長,集群計算的規模也在不斷擴大。然而集群規模的增大并不意味著絕對計算速度和并行效率的提升,其中影響并行應用程序計算性能發揮的主要瓶頸之一是消息傳遞通信設計不理想或使用不合理,導致全局通信使用頻率過高,造成通信堵塞、各種操作的響應時間持續延長和計算性能的下降。有數據表明,在大多數集群通信中,聚合通信開銷往往占據全部消息傳遞通信開銷的80%以上。因此,合理調整消息傳遞中聚合通信機制、降低全局通信流量應是改善現有集群計算環境的有效手段之一[1]。
本文基于MPI集群框架結構,通過分析單層型集群和樹型結構集群的聚合通信原理,提出了一種采用樹型結構的MPI集群系統設計方案,用以降低聚合通信的開銷,改善集群計算環境,同時也為集群的擴展提供更加靈活的手段。聚合通信包括很多全局操作(如廣播、同步、歸約、分發、收集)等,但很多聚合通信是由其他聚合通信的組合來實現的,本文選擇了有代表性的廣播和收集作為主要研究對象。
1 單層型結構與樹型結構
1.1 單層型結構介紹
單層型結構是目前大多數MPI集群工具所采用的框架結構。如圖1所示。該結構由一個主控節點和多個從屬節點組成,主控節點和每個從屬節點之間都建立了通信連接,實現聚合通信,從屬節點相互之間可以實現點到點通信[2]。
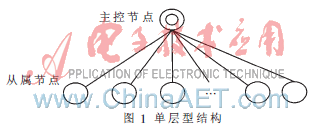
主控節點的功能主要包括與用戶進行交互,向從屬節點廣播、分發消息,收集、歸納從屬節點發來的消息,以及系統認證、網絡管理和遠程控制等。
從屬節點的功能主要用于計算、接收主控節點發來的各種控制命令、數據,根據控制命令在其節點機上進行相應的執行,然后將執行后的結果傳回給主控節點。
單層型結構集群的實現相對簡單,易于操作,且集群工具和應用軟件較多,所以應用廣泛。但是由于集群中只有一個主控節點,在聚合通信時,無論是一對多模式,多對多模式還是多對一模式,都要圍繞著主控節點進行,使得集群中全局通信流量所占比重較大。當集群節點數增加或計算量很大時,網絡負載極易到達額定上限,使得主控節點無法正常運行,計算性能下降。
單層型結構的消息廣播和消息收集的時間復雜度均為:O(n)
1.2 樹型結構介紹
樹型結構是針對單層型結構在消息廣播和消息收集方面速度慢、可擴展性差的弱點而提出的新的消息傳輸結構。圖2所示為典型的樹型結構,和單層型結構一樣,樹型結構也有主控節點(根節點)和從屬節點(葉子節點),且功能與單層型結構類似。不同的是,樹型結構中還包含分支節點,這些分支節點是樹的內部節點,沒有計算功能,也沒有系統認證、網絡管理和遠程控制等功能,只有對消息的轉發、分發和收集功能,所以也叫路由節點。圖2中,根節點與其下一層的分支節點有直接的通信連接,同樣每個分支節點都與其下一層的節點有直接通信連接,上層節點與下層節點可以實現聚合通信,而擁有同一個父親的同層節點之間可以進行點到點通信。除此以外,其他非同父節點相互之間沒有建立直接的通信連接。
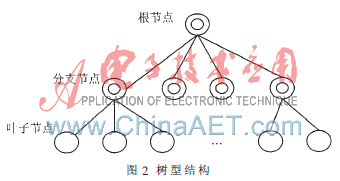
樹型結構集群可以將全局通信域劃分為多個子通信域,并且可以將主控節點的負載量分擔到各個分支節點上,降低全局通信量進而改善集群計算環境。同時隨著樹的深度增加,使得集群更易于擴展。但該集群實現起來比較復雜,且沒有專用的協議、應用軟件或集群工具的支持[3]。
樹型結構的消息廣播和消息收集的時間復雜度均為:O(logn)
2 樹型MPI的設計與實現
雖然使用樹型結構的集群系統可以改善聚合通信的效率,但其實現起來則相對復雜。主要原因是常用的MPI計算通信工具基于單層型集群設計,是在主控節點與若干計算節點之間的通信基礎之上實現的。為此,本文提出了一種利用IP轉發技術和MPI并行編程技術實現樹型結構的MPI集群系統設計方案。這里需要注意以下問題:
(1)根節點的設計
在構建集群網絡時,網絡安全和通信效率既相互依賴又相互制衡。若省去頻繁的核實用戶身份等安全方面的檢查,則可以省去一部分系統開銷,進而提高網絡通信效率,但集群網絡的安全性就無法保障;同樣,若犧牲通信效率而實現網絡安全,則集群計算的優勢將無法體現。通常的做法是采用內外網模式,即從屬節點和主控節點之間由內部網絡互聯,只有主控節點另有網絡通道通向外部網絡。這樣,由于內外網絡物理隔離,為網絡安全提供了保證,在內部網絡中可以省去頻繁的用戶身份認證等安全方面的開銷,從而為通信效率的提升留出空間。
根節點(主控節點)的設計也將采用內外網模式,在其機器上安裝兩塊網卡(網絡適配器),一塊接集群內部網,使用內部網絡設置,提供內部網絡服務(域名服務,NIS,NFS和RSH);另一塊接外部網,留出對外聯系的通道,兩網卡之間不提供路由、轉發等功能。
(2)分支節點的設計
樹形結構中的分支節點用于連接根節點(主控節點)和葉子節點(計算節點),在整個集群中發揮兩個作用:一個是承上啟下的連接作用,另一個則是對根節點(主控節點)的分擔作用,所以分支節點應具有路由和對消息的傳遞、分發和收集等功能。
分支節點的設計與根節點有類似之處。也是在其機器上安裝兩塊網卡,一塊連接上層節點(根節點或上層的分支節點),IP地址設置在上層節點的同一個網段內,默認網關指向上層節點(父節點),使其成為上層網絡的成員;另一塊連接下層節點(下層的分支節點或葉子節點),設置IP地址(最好與前一塊網卡的IP地址不同網段),為下層網絡提供網關服務。但若要在上下層兩個網絡實現路由,需要在分支節點上修改 /etc/sysctl.conf配置文件中的net.ipv4.ip_forward = 1(以Linux操作系統為平臺參考),使得本節點機IP轉發功能生效。這樣做的目的是既能實現上下兩層網絡之間的通信,同時又能阻止基于網絡第二層的廣播幀的傳播。
(3)域名的設計
在TCP/IP中,計算機之間的通信通過IP訪問來實現,但IP地址不容易編程和管理,所以整個集群系統需要為每個節點提供一套統一的命名機制。如圖3所示,Boot為根節點內部網卡的網絡標識,bran01-up和bran01-down為同一個分支節點機上的兩塊網卡上的網絡標識,前一塊為連接上層網絡的接口,后一塊為連接下層網絡的接口,leaf01為葉子節點的網絡標識。MPI編程環境可以通過此域名來區分、訪問運行在各個節點機上的進程(如MPI_Get_processor_name()函數)。

對于集群系統來說,集群中所有節點域名和IP地址的對應關系的建立是在/etc/hosts文件中描述的,不僅是因為它們經常用到,而且還因為該文件結構簡單,更易于快速查找。圖3所示的/etc/hosts.equiv文件可以為RSH(遠程shell命令)提供無口令遠程登錄,這也為各節點載入同一個計算程序二進制代碼和用戶身份的快速驗證提供了可能。
(4)進程組和通信域的設計
MPI中的通信域(Communicator)提供了一種組織和管理進程間通信的方法。每個通信域包括一組MPI進程,稱為進程組。這一組進程之間可以相互通信,而且這個通信域內的通信不會跨越通信域的邊界。這樣就提供了一種安全的消息傳遞機制,因為它隔離了內部和外部的通信,避免了不必要的同步。每個進程都至少在某個特定的通信域中,但有可能進程在多個通信域中,這就像某個人可以是多個組織的成員一樣。進程組由一個進程的有序序列進行描述,每個進程根據在序列中的位置被賦予一個進程號(0, 1, ...,N-1)[4]。
本文將根節點與其相鄰的下一層節點(孩子節點)劃定為一個進程組0,將分支節點1與其相鄰的下一層節點(孩子節點)劃定為進程組1,…,依此類推,直到所有分支節點或根節點都擁有自己的進程組為止,如圖4所示。由于每個分支節點或根節點都有兩塊網卡,所以將兩塊網卡分屬不同的進程組中,彼此互不包含。將全局通信域劃分成若干個子通信域,使得大量的消息傳遞開銷被限制在局部范圍內,大大降低了全局通信的頻率,從而提高了集群通信的性能。
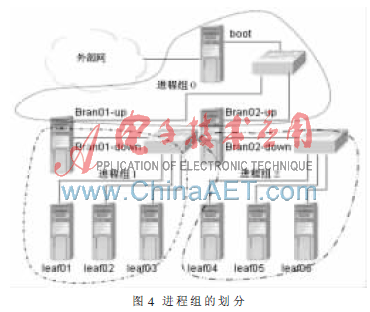
(5)組間通信
進程組劃分之后,形成相應的通信域,規避了大量節點間同步所消耗的開銷。但進程組之間也要進行通信,根節點需要將消息逐層傳遞到葉子節點,同樣葉子節點所計算出來的結果也是要逐層收集、規約到根節點,所以組間通信也是本系統實現的關鍵之一。這里,通過使用MPI組間通信函數(如MPI_Intercomm_create()函數)來實現組間消息的傳遞。
(6)葉子節點的設計
葉子節點作為主要計算節點,除了NIS、NFS、RSH客戶端軟件和MPI相關軟件外,盡量不再安裝其他軟件,以減少葉子節點額外的開銷。設置與其父節點同屬一個網段的IP地址,并將網關指向其父節點。如有必要可以精簡操作系統內核,使其盡量占用CPU時間少、占用內存少。
3 實驗結果與分析
3.1 實驗環境和方法
本實驗將先后搭建三組環境對這兩種結構的MPI集群進行測試,測試環境如下:
(1)第一組是具有2個計算節點的集群,單層型和樹型集群均由1個主控節點和兩個計算節點構成。
(2)第二組是擁有4個計算節點的集群,單層型是指1主控節點和4個計算節點構成,而樹型結構則是由1個根節點(主控節點),2個分支節點和4個計算節點構成,其中每個分支節點各連接兩個計算節點,對稱分布。
(3)第三組是具有6個計算節點的集群,如圖5所示。左圖為單層型MPI集群,擁有6個計算節點和1個主控節點;右圖為樹型集群,擁有1個根節點,2個分支節點和6個計算節點。

這其中每個節點包含一顆PIV處理器和2 GB內存,操作系統采用Redhat Linux Enterprise 5,并行集群軟件為OPEN MPI 1.3。由于條件所限,加之實驗規模較小,所以本實驗采用MPI自帶的函數MPI_Wtime()來采集MPI計算的開始和結束時間,取兩者的時間差作為程序的運行時間,并對其進行比較和分析,用MPI_Wtick()函數來監測MPI_Wtime()返回結果的精度。
在實驗用例設計上,考慮到兩種MPI集群的通信機制中的傳輸路徑不同,所以采用計算求解三對角方程組作為測試方案,主要測試通信和計算的平衡。
3.2 測度結果和分析
測試結果如表1、表2所示。
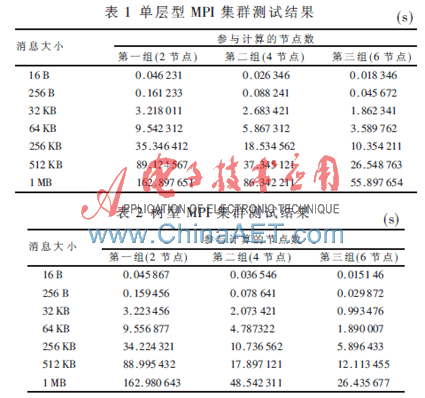
測試結果表明,在第一組的測試中,雙方的運行時間沒有明顯差別,這是由于它們都擁有1個主控節點和2個計算節點。雖然樹型結構在MPI聚合通信機制上有所改動,但影響有限,測試的結果基本相同。對于第二組的測試,測試結果差異較明顯,在傳輸短消息時,可以發現單層型集群的運算速度并不比樹型慢多少, 在16 B的情況單層型還優于樹型。這是因為樹型結構的集群中除了擁有和單層型相同數目的計算節點外,還有兩個分支節點(也叫路由節點),分支節點需要在兩個通信域之間傳遞處理消息,需要處理時間,所以樹型結構的消息傳輸時間除了消息廣播和收集時間外,還有域間轉發處理的時間。盡管在時間復雜度上樹型結構優于單層型結構,但在通信域中節點數較少、消息較小的情況下,兩者之間差距不是十分明顯,若再加上域間處理的時間,自然會出現這樣的情況。但當消息增大時,由于樹型結構中每個通信域的廣播和收集時間遠遠小于單層結構的廣播和收集時間,從而抵消了分支節點處理消息的時間,所以樹型的整體運算時間明顯小于單層型的運算時間。對于第三組的測試,樹型的整體運算時間明顯優于單層型集群,幾乎相當于同級別單層型集群的1/2。這是由于隨著計算節點的增加,樹型MPI集群的優勢明顯發揮出來,尤其是聚合通信方面。
由上分析表明,基于樹型MPI并行計算集群的設計方案是可行的。在該方案上構建的MPI集群系統可以使消息廣播和消息收集的速度明顯提高,使得全局通信使用頻率明顯下降,從而提升了集群整體計算速度。同時,由于樹型結構的特點,使得集群的擴展更加輕松。盡管從理論上可知隨著節點數的增加樹型MPI的集群的優勢將更加凸顯,但是由于實驗條件的限制,只能對集群通信系統做初步驗證。所以希望在未來的研發工作中能夠引入更科學的評測體系,不斷地論證和完善該系統,為提升中小型MPI集群性能提供幫助。
參考文獻
[1] 劉洋,曹建文,李玉成. 聚合通信模型的測試與分析[J].計算機工程與應用,2006(9):30-33.
[2] CHEN C P. The parallel technologies (PaCT-2003)[C]. Nizhni Novgorod, Russia.2003.
[3] ROCH P C, ARNOLD D C, MILLER B P. MRNet: A software-based multicast/reduction network for scalable Tools[A]. Phoenix, Arizona, 2003.
[4] 莫則堯,袁國興.消息傳遞并行編程環境[M].北京:科學出版社,2001.