
摘 要: 設計了一種閱卷系統,允許使用者使用任何顏色的圓珠筆、鋼筆或鉛筆在一般紙張的固定位置上涂寫如“√”、“╳”、“○”等手寫符號完成答題,由閱卷系統采用圖像識別技術對答題卡圖像進行預處理、符號識別、統計判分,實現閱卷自動化。實驗表明,由于結構方面的相似性,本閱卷系統識別錯誤集中在符號“√”、“╳”上,而對符號“○”的識別基本無誤。
關鍵詞: 圖像識別;字符識別;閱卷系統
高校學生的期末考試是普通高等學校管理的一項重要工作,它是根據國家對高等學校學生德智體全面發展的要求,按照統一的原則、方法和程序,對學生學習和行為的表現進行階段和全程的質量考核、記載、評價和處理。目前客觀題型較多的英語考試或計算機基礎考試均實現了閱卷自動化,無需教師干預,既能加快試卷反饋的速度,又能保證公平公正。傳統的閱卷系統利用光學標記閱讀機的光電變換原理,對填涂在答題卡上的內容進行高速采集,然后進入計算機處理[1]。但是它對答題卡紙張和印刷質量要求太高,如套印誤差和剪切誤差必須分別控制在0.1 mm和0.2 mm以內;對使用者涂寫要求太高,限制太多,如需要用專用鉛筆涂滿長方條,不得涂出長方條外,整張答題卡涂寫要深淺一致等;機械傳動機構復雜、使用壽命短、維護量大、設備一致性差[2]。
本文提出一種基于圖像識別的閱卷系統,允許使用者使用任何顏色的圓珠筆、鋼筆或鉛筆在一般紙張的固定位置上涂寫如“√”、“╳”、“○”等手寫符號完成答題,由閱卷系統采用圖像識別技術自動識別答題卡信息,實現閱卷自動化。本系統與傳統的光學標記閱讀機閱卷系統的不同之處在于,本閱卷系統對答題卡紙張和填涂符號均無特殊要求,無需特制答題卡,無特殊涂寫要求[3]。
1 系統實現流程及模塊組成
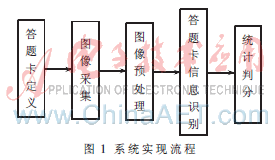
(1)設計和定義答題卡,將允許用戶填寫的手寫符號限定在一定的矩形區域內;
(2)通過CCD采像設備采集答題卡圖像,經掃描、采樣、量化等過程,同時將答題卡圖像以JPG格式保存在主機內存和硬盤里;
(3)對答題卡圖像進行預處理,包括粘連字符分割、灰度變換、二值化、圖像偏斜糾正、平滑和細化等過程,以將答題卡固有的紙張問題、書寫不規范、答題卡傳動機械定位精度所帶來的干擾因素排除掉,并為后續的識別工作做好準備[4];
(4)對答題卡信息進行識別。通過圖像分析抽取圖像,并經過綜合特征提取,結合答題卡表格的邏輯結構和幾何結構,準確識別填涂在矩形塊位置上的“√”、“╳”、“○”等手寫符號得到答題信息。答題卡識別算法的優劣決定了整個系統的性能(如識別的精度、可靠性等),是整個軟件系統中最重要的部分;
(5)對識別的答題信息進行加工、整理、分析和統計,結合軟件的設置對答題卡信息進行判分。
綜上所述,系統實現流程如圖1所示。
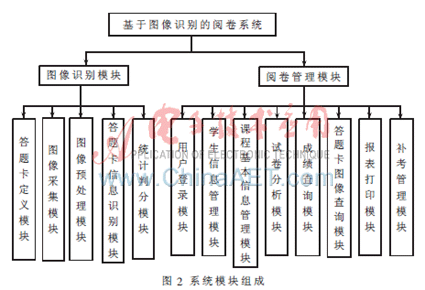
為了便于學生和教師查詢和分析閱卷結果,本閱卷系統還設置了用戶登錄模塊、學生信息管理模塊、課程基本信息管理模塊、試卷分析模塊、成績查詢模塊、答題卡圖像查詢模塊、報表打印模塊和補考管理模塊。其中試卷分析模塊對試卷的各項數據進行分析和統計,包括最高分、最低分、平均數、及格率方差、標準差等,完成試卷分析功能;答題卡圖像查詢模塊允許學生通過姓名查詢存儲在硬盤中的答題卡圖片;補考管理模塊統計不及格、缺考或舞弊學生信息,生成補考表;報表打印模塊完成答題卡圖片、成績報告單、試卷分析報告和補考表等的打印功能。系統模塊組成如圖2所示。
2 系統主要實現技術
2.1答題卡設計
答題卡設計成表格的形式,由試卷答題卡基本信息、考生基本信息、答題卡填寫說明及題目選項列表組成,考生用“√”、“╳”、“○”等手寫符號在相應的矩形框中選擇答案。答題卡示例如圖3所示。

答題卡版面與普通表格一樣具有幾何結構和邏輯結構,幾何結構反映了所填寫的信息區域的位置和大小,邏輯結構則表示答題卡中所填寫信息的實際意義以及填寫信息與填寫項之間的對應關系。
在傳統的光學標記閱讀機閱卷系統中,答題卡的幾何結構大部分都是采用定位標記塊進行描述,這種描述方法具有很多缺點,如浪費版面空間、缺乏靈活性、版面設計比較復雜、對印刷質量要求高、不便于修改等,而且定位標記塊看起來也不美觀。在本系統答題卡版面中,填寫信息在幾何結構上可以看成由若干個互不相交的矩形塊組成,它們組成了答題卡版面的最小單位[5],可以以答題卡的邊框線建立二維坐標系,以矩形的對角頂點坐標來描述矩形塊的位置和大小,完成對答題卡的幾何結構描述,該方法簡潔、靈活,便于識別。
答題卡的邏輯結構描述是定義矩形塊的屬性。矩形塊的屬性包括對填寫項以“√”、“╳”、“○”表示的選擇或者不選擇。
本系統采用文檔結構描述語言同時對幾何結構和邏輯結構進行描述。設一張答題卡包含n個填寫有信息的矩形塊B1,B2,...,Bn, 矩形塊之間存在著上下結構和左右結構的幾何位置關系,其邏輯順序一般是從上到下、從左到右,在描述文檔結構時也采用這種順序,則文檔結構描述語言DDL 表示如下:

其中i 是答題卡的序號;n是矩形塊的總數;xi為矩形塊在水平方向的位置;yi為矩形塊在垂直方向的位置;li為矩形塊的長度;wi為矩形塊的寬度;attri表示矩形塊的屬性,當attri為0時,表示該矩形塊的填寫內容為待識別的字符,attri為1時,矩形塊作為圖像保存。
將答題卡設計成常見的表格形式,一方面它和一般考試用到的答題卡的形式類似,符合人們的使用習慣和書寫習慣;另一方面可以利用文檔描述語言對它的幾何結構和邏輯結構進行描述,以便更好地對矩形框內的字符特征進行提取與識別,辨別矩形框中的字符,與標準答案比對,對考生客觀題進行判分。
2.2 答題卡信息識別
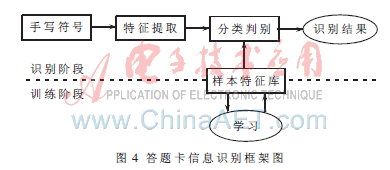
本系統采用漢字識別方法中的統計決策方法對手寫字符進行識別,如圖4所示,首先提取字符特征,對字符進行分類判別,經過訓練和識別兩個階段,最后識別出字符[6]。訓練階段,收集日常人們習慣的手寫符號為樣本,經過篩選分類建立樣本庫,以便對待識別字符進行分類和識別。識別階段,將待識別符號的特征與訓練階段中所建立的標準樣本特征比較,計算最大相似度以判別該手寫符號所屬的類別[7]。
2.2.1 字符特征提取
學生在答題過程中由于緊張和個人原因,寫出的√、╳、○等答題符號往往千變萬化。為準確識別這些手寫符號,需要進行字符結構特征提取,將最能體現這個字符特點和字符間差異的結構特征提取出來。本系統提取的特征是以下特征的組合。
(1)點特征
點特征是一種重要的結構特征,是指字符筆畫中的端點。端點反映了字符中筆畫的起點和終點信息,與該點相連的點數為 1。
(2)筆畫密度特征
筆畫密度特征是取得符號水平方向筆畫密度函數d(x)和垂直方向的筆畫密度函數d(y),然后進行相同項合并[1]。如圖5所示,符號“○”水平方向筆劃密度函數d(x)和垂直方向的筆劃密度函數d(y)分別是: d(x)=(1,...,1,2,...,2,1,...,1),d(y)=(1,...,1,2,...,2,1,...,1),則合并后筆畫密度可表示為d(x)=d(y)=(1,2,1)。

(3)基于鏈碼方法的結構特征
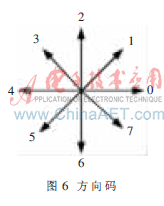
從曲線起點開始與其相連的像素點有8種可能的方向:k×45°(k=0,1,…,7),如圖6所示, 如果兩個像素點間的連線方向為k×45°,就用“k”作為這條連線的代碼,則一條曲線最終可近似地用下式表示:
An=a1a2…an,ai∈{0,1,2,…,7}, i=1,2,…,n
(4)孔洞特征
在二值圖像中,被目標像素1包圍的背景像素0(的集合)稱為孔洞(hole)。在字符的骨架線的鏈碼形成過程中,若搜索到的下一點就是該骨架線的搜索起始點,同時己形成的骨架鏈碼碼長超過了一定的閾值,則認為搜索到一個孔洞[5]。
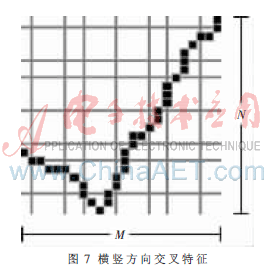
(5)橫豎方向交叉特征
橫向或縱向掃描字符,某一行或列的像素由白變黑的次數就是該行或列的橫或縱向交叉特征。本系統將橫豎兩個方向距離不等的7條線作用于字符,計算水平和垂直方向與字符的交叉數,如圖7所示。
2.2.2 符號模型庫建立
答題卡信息識別的訓練階段需要建立符號模型庫,以便對待識別手寫符號進行分類和識別。符號模型庫建立的好壞直接影響分類器的應用,從而影響手寫符號識別效果[5]。
由于手寫符號的多樣性,需要選擇某一類手寫符號中具有代表性的多個樣本來構造標準樣本,本系統采用手寫字符樣本特征向量的均值來描述類目標。設有n個符號類,每個符號類中有a個訓練樣本,每個樣本有b個符號特征,每個符號類中樣本的特征記為fkj,k為樣本特征序號,j為各個手寫符號的樣本序號,則第i個目標類特征的均值為P(i),即:
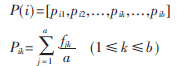
每次計算Pik時,k為大于等于1小于等于b的固定值。Pik為對于第i個目標類中a個樣本中各個樣本對應第k個特征值的均值。
2.2.3 手寫符號識別
對答題卡中矩形框信息識別包括兩個方面,一是識別矩形框中是否有字符,二是識別具體是哪種字符。其中識別是否書寫了字符比較簡單,只要比較增強對比度后的矩形框圖像與已知填有信息的矩形框的均方差大小,即可識別是否有字符,因為空白的矩形框和被書寫的矩形框均方差差別很大。下面主要介紹怎樣識別矩形框中的具體字符。
手寫符號識別就是在提取到符號的特征向量之后,依據一定的判別函數來判定出某一圖形點陣具體代表的是哪一個手寫符號。
判別函數可以先簡單地作如下定義:考慮有P1,P2,...,Pm個符號類別,假使每類有一個標準樣本,則共有m個標準樣本,分別表示為k1,k2,...,km。任意一符號特征向量X和第i個(i=1,2,...,m)標準樣本間的“相似度”為Ri。計算待識別的符號特征向量X與每類標準樣本之間的“相似度”[7],并將X分到與它“相似度”最大的類別,即對所有的j不等于i,若Di>Dj,則X就屬于Pi類符號。
系統采用基于最鄰近域分類器的模板匹配算法來對手寫符號進行識別。
首先定義字符特征向量,經過前面的特征提取分析,該特征向量為一個16維向量,X={x1,x2,..,x16},具體定義為:
x1:孔洞數;
x2:端點數;
x3~x9:7條水平線與字符的交叉次數;
x10~x16:7條豎直線與字符的交叉次數。
通過度量待識別字符和樣本庫中樣本字符的接近程度,確立最近分類的一個準則。在最鄰近分類中,經常使用的是相似度。如圖8所示,在提取了待識字符的特征向量并建立了字符庫后,將待識別字符和樣本庫中第i個樣本的特征向量之間求近似度R(X,G)。R(X,G)定義如下:
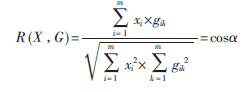
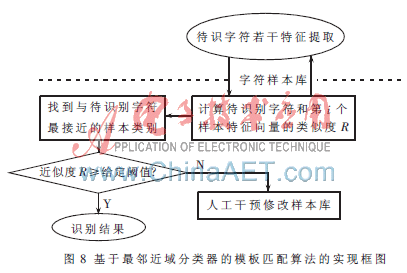
式中,xi為待識別符號特征向量的第i個分量,gik為樣本庫中第i個標準樣本的第k個分量,m為樣本類別數。分子為向量X,G之間的內積,分母分別為向量X、G的模。α是向量X,G在m維空間的夾角。顯然,當X、G兩個向量完全相同時,其夾角為0,R(X,G)=1,它們的距離D(X,G)=0,即相似度最大。求出最大Rr(X,G),若Rr(X,G)≥給定閾值,即可找到與待識別字符最接近的樣本類別,否則人工干預并修改樣本庫[7]。
3 實驗結果與分析
實驗采用CCD攝像頭采集答題卡圖像,經圖像預處理、若干特征提取、信息識別等過程,判定矩形框中有無字符、是什么字符,最后對答題卡信息分析和統計。實驗采用100份試卷作為樣本,對20份試卷進行測試,結果發現識別錯誤的手寫符號主要是“√”和“╳”,原因在于這兩者在結構方面相似,而符號“○”的識別率達到100%。
本系統將圖像預處理、字符特征提取與圖像識別等技術應用于閱卷系統的開發,實現了閱卷自動化,加快了成績考核的速度,改善了教學管理環境。相比于傳統的基于光學標記閱讀機的閱卷系統,本系統利用圖像識別技術實現閱卷自動化,不需要特殊的答題卡,考生也可以隨意使用各種“√”、“╳”、“○”等手寫符號進行答題,不必用指定的2B鉛筆填涂矩形塊,更符合人們的習慣。
參考文獻
[1] 王虎.基于圖像識別的標記閱讀機及選舉計票系統研究[D].合肥:安徽大學,2006.
[2] 張婷.基于圖像識別技術的光學標記閱讀機的研究與應用[D].合肥:安徽大學,2007.
[3] 吳元君,張婷,雷驚鵬.一種改進的OMR 技術在標準化考試中的應用[J].計算機教育,2007(13):250-272.
[4] 丁慧東.脫機手寫體漢字識別研究[D].長春:東北師范大學,2006.
[5] 龐東虎,金偉杰.英文字符特征提取系統[J].計算機仿真,2007,24(12):208-210.
[6] 楊玲,毛以芳,吳天愛.基于多特征多分類器的脫機手寫漢字識別研究[J].計算機與網絡,2008(01):217-217.
[7] 覃勝,劉曉明.基于圖像的OMR技術的實現[J].電子技術應用,2003,29(10):17-19.
[8] 翁功平.光標閱讀機OMR原理的設計與實現[J].工業控制計算機,2010,23(04):61-62.