
摘? 要: 介紹語音信號LPC分析中部分相關系數的舒爾遞推算法的FPGA實現,給出了電路設計思想及具體電路結構,并對其工作過程進行了詳細分析說明,為嵌入式系統設計提供了一種有效手段。
關鍵詞: 部分相關系數?舒爾遞推算法?FPGA 并行處理技術
?
隨著語音技術應用的發展,越來越多的語音信號數字處理系統需要按照實時方式或在線方式工作,特別在嵌入式系統設計中,對系統的硬件環境要求更高。隨著語音處理算法的日益復雜,用普通處理器對語音信號進行實時處理,已顯得力不從心。本文將采用新一代現場可編程門陣列FLEX10K系列的FPGA芯片實現語音信號的LPC分析,并通過舒爾(Schur)遞推算法,提取語音信號處理中的重要參數——部分相關系數,即PARCOR系數。
1? LPC分析及舒爾遞推算法
1.1 LPC分析基本原理
線性預測分析(LPC)是對一給定的時域離散線性系統用輸出信號的過去值的線性組合來估計即將到來的輸出值。即某一時刻n的語音信號的估計值為:
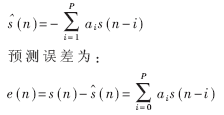 ??????
??????
按均方誤差最小準則,即LMS算法,可求得預測器最佳預測系數ai應滿足下列方程組:
??? 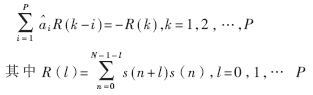 ?
?
????這組方程稱為LPC正則方程,其中R(l)稱為自關函數,它們是進行LPC分析的基礎。
1.2 舒爾遞推算法
??? 將正則方程作適當變換,定義一個變量Ql(m)如下:
??? 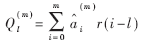 ????
????
? 其中r(l)=R(l)/R(0)為歸一化自關函數。
根據Ql(m)的性質和正交定理[1]可證明部分相關系數K(m)與Ql(m)有下列關系:
? 
由于部分相關系數K(1)~K(P)與最佳預測系數a1(P)~aP(P)間存在簡單對應關系,因而部分相關系數K(m)被廣泛應用于語音識別、語音合成和低速語音編譯器中。
2 系統設計
2.1 系統總體設計
由于語音信號具有短時平穩性,因此在進行處理時需進行分幀處理,然后逐幀對語音信號進行LPC分析。本系統中,語音信號S(n)的精度為12位,采樣率為20k,幀長為10ms,相應于每幀有200個采樣點,每幀提取的部分相關系數K(m)的階數取為12。
對取出的每幀語音S(n)還需進行加窗處理,即用窗函數W(n)乘S(n),形成加窗語音信號SW(n)。為減小Gibbs效應的影響,本系統采用的窗函數為哈明窗。
為實現語音信號的LPC分析過程,選擇FLEX10K系列中的EPF10K100器件作為目標芯片進行設計,因其具有獨特的嵌入式陣列塊EAB而特別適合于對數字信號進行處理[2-4]。系統設計中,采用自頂向下的設計思想,在頂層采用電路原理圖的設計方法將系統分為幾個功能模塊,在底層則采用VHDL語言來實現各功能模塊的設計。為保證系統整體的處理速度,電路設計采用了流水線作業方式,以數據流驅動各模塊協調工作,同時在一些影響系統整體速度的環節采用了并行處理技術,很好地解決了制約系統速度的“瓶頸”。
系統的原理框圖如圖1所示。圖中U3、U10分別為由EAB構成的200×12bit和12×12bit的雙口RAM陣列;U9為由EAB構成的200×12bit的ROM查找表,內置n=0~199的窗函數值W(n);U2、U4、U6為數據緩沖器;U7、U8分別為自關函數模塊和舒爾遞推算法模塊;U1為多路轉換開關;U5是12位乘法器。
?

?
系統工作原理如下:將一幀語音信號S(n)經U1送入U3,同時啟動加窗過程,窗函數值W(n)通過查找ROM表U9獲得,將取出的Wn和Sn送入乘法器U5相乘,乘積經U2和U1又送回U3,得到加窗語音信號SW(n),然后將SW(n)送入自關函數模塊U7算出歸一化自關函數r(n),再將r(n)送入舒爾遞推模塊求出部分相關系數K(m),存入U10。至此,一幀數據的LPC分析即告結束。
2.2 自關函數模塊
自關函數的計算是影響系統速度的關鍵環節,它要進行大量的乘積累加操作。為提高系統運行速度,將加窗語音信號SW(n)同時存入兩組RAM,采用并行取數的方式,同時取出參與運算的兩個量,進行乘法運算,運算結果立即送入累加器進行累加。而此時乘法器又可進行下一對數據的乘積運算。整個過程中,乘法器和累加器一直在并行工作,從而保證了系統的流水線操作持續進行,最大限度地保證了系統的運行速度。
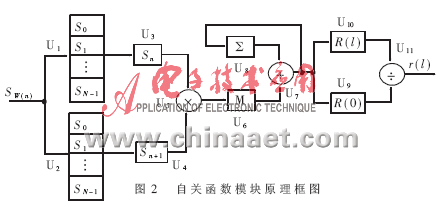
自關函數模塊的原理框圖如圖2所示。圖中U1、U2為EAB構成的200×12bit的雙口RAM陣列;U8是帶清零功能的數據寄存器,U7為加法器,它們二者共同構成累加器,為保證中間運算結果的精度,累加器的寬度為32位;U3、U4、U6、U9、U10為數據寄存器;U5為12位乘法器,乘積為24位;U11為32位除法器,商取16位。
?
?
該模塊的工作過程是:將前面得到的加窗語音信號SW(n)同時存入U1和U2,然后按要求從中同時取出兩乘數Sn和Sn+l送入乘法器U5進行乘運算,將乘積作為一個操作數同U8中的數進行累加。U8起始值被置為零,以后的值就是各次累加的和,最后一次累加的結果就是自關函數R(l)的值。然后再將它的值送入U10,將它同U9中的R(0)相除即得歸一化的自關函數值r(l)。整個過程中,由于采用了并行處理技術,乘法器U5和累加器U7與U8一直處于工作狀態,從而保證了系統的高速運行。
2.3 舒爾遞推模塊
舒爾遞推算法一個很重要的特點是在整個遞推過程中全部參與運算的量的初值、中間值和最終值皆小于1,因此特別適宜于采用定點運算的硬件系統來實現。該模塊的設計也采用雙RAM結構和同時取數同時運算的并行處理技術,所有運算單元的精度都是16位,每處理一次遞推過程,就輸出一個K(m)值。
舒爾遞推模塊的原理框圖如圖3所示。圖中U2、U3為12×16bit的雙口RAM;U4、U6、U7、U8、U9、U11、U13為數據寄存器;U5、U10、U12分別為16位的除法器、乘法器和加法器;U1為多路轉換開關。該模塊的工作過程是:當歸一化自關函數r(l)通過U1送入U2和U3后,立即從中取出Qm和Q0送入除法器U5進行除運算,除得的結果送入U8;與此同時又分別從U2和U3中同時取出Ql和Qm-l,將Qm-l與Km在U10相乘后,送入U11,接著與Ql在U12進行相加,將結果經U13、U1重新送回U2和U3,接著又進行下一輪遞推,該過程一直要進行到遞推階數完成。在每一次遞推過程中,當U12在進行當前數據的加運算時,U10就可進行下一個數據的乘運算。這樣整個過程就可在連續的流水線方式不間斷地進行。
?

?
2.4 算術運算單元
本系統所用到的算術運算單元有加法器、乘法器和除法器三種。加法器采用標準的全加器來構成,而乘法器則采用2的補碼的BOOTH乘法器。下面介紹除法器的設計思想和工作原理。
由于本系統所使用的除法運算都是商小于1的除法,而且除法運算又比乘法運算少得多,因此對速度的影響也較小。綜合考慮速度和資源占用兩方面因素后,設計了下面的算法來實現除法器。設有兩個數A和B,A是被除數,B是除數,現在求它們的商Q=A/B,Q<1。現將Q表示成下列形式:

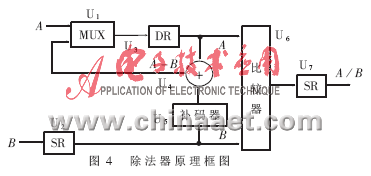
由于上述算法只需進行減法運算和除2運算,所以非常便于用硬件實現,據此算法設計的除法器原理框圖如圖4所示。圖中U2為并入并出移位寄存器,每右移一位,實現一次除2操作;U5為補碼器,它由反相器和加一電路構成,用于對B求補碼;U7為串入并出移位寄存器;U6為比較器,用于對A、B兩輸入數進行比較,若A≥B,則輸出“1”,否則輸出“0”;U3為數據寄存器;U1為多路轉換器;U4為加法器。該電路按下述原理工作:被除數A經U1送入U3并加到比較器U6的A端,除數B送入U2后右移一位再加到U6的B端。經U6比較后,若輸出“1”,則先將U6的輸出移入移位寄存器U7,再將A與B送入由U4和U5組成的減法器進行減法運算,所得差值再經U1送入U3;若輸出為“0”,則僅將U6的輸出移入U7即可。該步完成后,又將U2右移一位,再重復上述過程。整個操作一共要進行K次,最后U7中的數即為A/B的商。
?
?
在本系統中,將LPC分析與FPGA技術結合,充分利用了FPGA作為一種快速、高效的硬件平臺在數字信號處理領域所具有的獨特優勢,實現了語音信號特征參數的快速提取,為語音信號的進一步處理打下基礎。本系統采用50MHz的時鐘頻率進行工作。為考察其工作性能,對其整體性能指標進行了評估。由于影響整個系統速度的是乘法累加運算,因此它的工作性能也就決定了系統的性能。在求歸一化自關函數r(l)過程中,涉及到近200次的乘積累加,采用并行處理技術和流水線操作方式的FPGA則可以用接近50MHz的數據速率進行工作,整個系統的性能同其他芯片相比約提高40%~60%,因此用FPGA技術來處理語音信號具有得天獨厚的優點。
??? 本系統除具有處理速度快的特點外,還具有獨立靈活的輸入輸出接口及一組檢測和控制信號線,可以方便地同任何一種處理器直接連接。由于FPGA自身所具有的抗干擾能力強、可靠性高的優點,本系統可廣泛應用于自動控制、工業機器人、語音合成和語音編譯碼等領域,特別對嵌入式系統的設計具有重要意義。
?
參考文獻
1 楊行峻,遲惠生.語音信號數字處理.北京:電子工業出版社,1995
2 劉寶琴.ALTERA可編程邏輯器件及其應用.北京:清華大學出版社,1995
3 Altera. MAX+PLUSⅡ? Programmable? Logic? Development? System? AHDL,1997
4 FLEX Embedded Programmable Logic Family Data Sheet.ALTERA Corporation,1998