
摘 要: 研究了利用盲源分離" title="盲源分離">盲源分離理論解決語音識別" title="語音識別">語音識別之前的語音凈化問題。基于MSICA算法良好的性能、低復雜度和實時性,設計了以TI公司的TMS320C6416數字信號處理器為內核的語音凈化系統。該系統可以使語音識別系統" title="語音識別系統">語音識別系統獲得純凈語音,從而有效提高語音識別系統的識別率和魯棒性。
關鍵詞: 盲源分離 DSP 語音識別 語音凈化
目前針對語音識別提出了很多算法,但是這些研究基本上都是基于較為純凈的語音環境,一旦待識別的環境中有噪聲和干擾,語音識別就會受到嚴重影響。因為大多數語音識別的語音模板基本上是在無噪聲和無混響的“純凈”環境中采集、轉換而成。而現實環境中不可避免地存在干擾和噪聲,包括其他人的聲音和回聲等,這些噪聲有時很強,使語音識別系統的性能大大降低甚至癱瘓。已有的信號去噪、參數去噪和抗噪識別等方法都有一定的局限。如果能實現噪聲和語音的自動分離,即在識別前就獲得較為純凈的語音,可以徹底解決噪聲環境下的識別問題。近年來取得很大進展的盲源分離為噪聲和語音的分離提供了可能。盲源分離(Blind Source Separation)的算法眾多且運算復雜,經比較,其中T. Nishikawa等人提出的分階段 ICA方法(MSICA[1])適合有混響的噪聲環境中的語音分離問題。經過計算機仿真,MSICA算法分離一段7s的語音要用時10ms以上,計算機和低速的DSPs很難滿足實時要求。針對這一算法,設計了一套以TI的TMS320C6416 DSP(簡稱6416)芯片為內核的語音凈化系統。6416的時鐘速度高達720MHz,經過使用MSICA算法的測試,該系統可以實時地對語音識別的信號進行凈化處理,有效地提高語音識別系統的抗噪性和魯棒性。
1 算法描述
1.1 語音識別信號的混合模型
1.1.1 卷積混合一般模型[3]
語音信號的混合模型已從瞬時模型發展到卷積模型,相比瞬時模型而言卷積模型更接近真實環境。麥克風所測是卷積混迭信號,即源信號及其濾波與延遲的混迭信號的線性組合再加上其它噪聲,如(1)式所示。

式(1)中, sj(t), j=1, ...,N為信號源,且各源信號相互獨立;xi(t),i=1,...,N為N個觀測數據向量,其元素是各個麥克風得到的輸入。所以觀測信號xi(t)是每個源信號sj(t)經過延時τij,并乘以因子aij(t)(沖擊響應)后疊加,最后加上噪聲ni(t)。
1.1.2 針對語音識別的簡化混合模型
一般的語音識別系統只有一個麥克風,根據盲源分離理論,麥克風數應不少于信源數,所以采用主副兩個麥克風輸入待識別語音,為簡化處理假定只有主講話者聲音s1和背景噪聲s2(此背景噪聲包括經過延遲的回聲)兩個聲源。可得如圖1的混合模型。
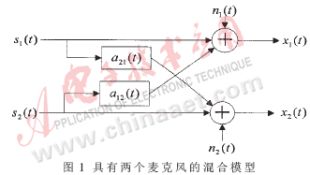
信號源s1到達兩個麥克風的時間間隔為τ21,且幅度值不同;s2到達兩個麥克風的時間間隔為τ12,幅度值也不同。又因為主信號源s1非常靠近兩個麥克風,所以認為τ21比τ12小很多,且趨于零。于是得到相應的模型表達式的簡化形式:
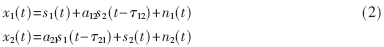
1.2 MSICA算法及其實現步驟
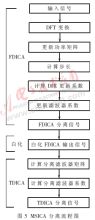
傳統采用頻域ICA(FDICA)或者時域ICA(TDICA)方法,單一的方法在真實環境中缺點很明顯,分離效果在混響環境中受到很大影響。然而一種時頻域結合多級分離的混合型ICA算法——MSICA[1] 算法可以有效解決這一問題。
該算法主要由三個步驟組成:首先,利用FDICA的高穩態性的優點在一定程度上分離源信號;為了簡化后續計算,白化FDICA分離出來的信號;接著,把白化后的FDICA輸出信號當作TDICA的輸入信號" title="輸入信號">輸入信號,并用TDICA分離殘留的交叉干擾分量;最后,TDICA的輸出信號即為分離信號。算法框圖如圖2所示。
2 DSP硬件系統設計
2.1 硬件結構
為實現上述算法設計了DSP語音分離系統,該系統主要參數如下:
·TMS320C6416 DSP;
·16M words FLASH ROM;
·兩個EMIF: 64-Bit EMIFA 和16-Bit EMIFB;
·133MHz的16MB SDRAM;
·兩塊16-bit 立體聲CODEC:TLV320AD50。
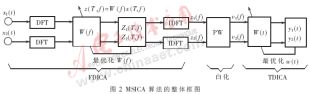
TMS320C6416有很高的信號處理能力以及豐富的片內存儲器和片內外設,且有兩級內部存儲結構。第一級L1緩存包含各為16KB的程序和數據存儲器,第二級L2包含1024KB的存儲空間。第一級只能作為緩存而第二級可以被設置為部分靜態RAM和部分緩存。在語音凈化系統中,設置L2為4通道256KB緩存和768KB靜態RAM。這種配置使用了最大允許的緩存,是因為MSICA算法將處理大量的數據,訪問外部存儲器會有瓶頸,而大緩存可以將諸如中斷服務程序、常用函數的代碼、軟件堆棧等關鍵數據段和反復使用的系數存儲于片內存儲器中,從而大大提高內部存儲空間的使用效率。6416的兩個多通道緩沖串口(McBSP)用作數據的輸入輸出端口。模擬接口芯片TLV320AD50可以提供16bit的數/模、模/數轉換,最大轉換率是22.5kHz。采樣率為8kHz,兩個TLV320AD50分別通過McBSP與TMS320C6416相連。兩路混合語音信號通過模擬接口電路轉化為數字信號,兩路數字信號通過TMS320C6416的兩個McBSP輸入,根據語音特征存儲器中存儲的語音特征進行語音分離,分離出純凈的待識別語音,進行語音識別,最后輸出識別結果。系統框圖見圖3。
2.2 軟件流程
系統上電后,存儲在FLASH ROM中的程序將載入TMS320C6416的片內RAM中,程序對寄存器、中斷向量表和編碼進行初始化并對片內McBSP進行配置,完成這些初始化的任務后系統采集并處理語音信號。系統首先對目前狀態進行辨識。開機后的狀態分為非識別狀態和識別狀態,非識別狀態下系統將采集純正語音信號,提取出語音特征送入存儲器中作為模板;識別狀態下首先參考純凈語音的特征對采集的雙路混合信號進行分離,獲得純凈的待識別語音,最后送入識別系統完成語音識別。整個流程見圖4。
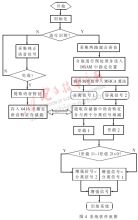
具體分離步驟在初始化之后,主函數程序進入一個等待循環,在一個新的采樣輸入被獲取之后與中斷服務程序(ISR)一起工作并調用分離程序。第一步,信號首先通過TI的DFT程序變換到頻域。系統使用最前面的幾個塊(例如取5塊)來估計輸入信號x1和x2每個頻率分量的功率矩陣。流程圖(見圖5)中的變量P表示正在處理的塊數。對于接下來的每一塊(P≥5),系統通過指數平均來更新輸入信號的功率矩陣,以計算出梯度。然后計算步長u12、u21 和差分脈沖響應濾波器ΔH12、ΔH21的更新系數。最后確定更新系數和DRIR濾波器系數,在頻域對輸入信號進行初步分離。第二步,白化程序對FDICA輸出信號進行白化處理,以去除信號的相關性。第三步,首先通過最小化非負代價函數計算分離濾波器矩陣和分離濾波器系數,然后帶入白化后的信號求得TDICA輸出信號。
2.3 代碼優化
為了進行實時的混合語音分離并識別,分離算法必須在盡可能短的時間(如1~2s)內完成。在本系統中,通過CCS對C源代碼進行編譯,并對分離算法的一些關鍵模塊從內聯函數" title="內聯函數">內聯函數替換、數據讀寫、循環體優化、函數拆并、C級優化等方面進行優化設計,以達到充分利用CPU、存儲器等資源,提高算法運行速度,滿足實時性要求。
(1) 內聯函數優化
通過內聯函數替換提高代碼性能。內聯函數直接與匯編指令相對應,通過使用它們,C編譯器能達到更好的編譯效果,并充分利用系統資源。C6416提供豐富的內聯函數,涵蓋了各種數據類型的乘、加、移位等操作。實驗結果表明,內聯函數替換是提高代碼性能最簡單、直接有效的方法。
(2) 數據讀寫優化
充分利用C6416的雙字存取指令和packing/unpacking方式提高代碼的運行速度。
(3) 循環體優化
通過軟件流水工具(Software Pipeline)適當安排循環指令,使多次迭代并行執行,以達到優化代碼的目的。
(4) 函數拆并優化
將某些大函數拆開成多個小函數或相反,以提高程序的運行速度。對FDICA和TDICA等大程序中某些常用的分支,可將其拆分以減少判斷、跳轉操作。對于某些簡單的小函數,將其合并成大函數有助于減少程序調用開銷。
(5) C級優化[2]
在定點DSP上進行浮點運算會影響C源代碼的性能。因此,第一個優化任務就是將源碼中運算比較密集的部分(如分離濾波器矩陣和分離濾波器系數的計算)轉換成定點的算法。此外,影響系統性能的一個重要原因是沒有有效利用DSP的并行計算能力,TMS320C6416為最優化這些并行操作的打包數據處理提供了特殊的指令。系統另一個瓶頸是對外部存儲器的訪問。對混合語音的分離需要處理大量的數據,存儲和訪問可能是DSP系統的最大瓶頸。通過使用緩存可以緩解瓶頸,優化在外部和內部存儲器中的數據定位可以提高系統的性能。最后,使用C編譯器的最優化選項編譯代碼。
上述的優化并非已經完全,在后續的研究中代碼可以進一步優化,如可改進以下幾處:首先,使用DMA以提高存儲器訪問的性能并減少存儲器消耗;其次,為了避免浮點溢出可以將代碼全部轉換為定點,對代碼中的關鍵循環進行更好的組織以實現軟件流水線;最后,為了最大程度提高性能可以使用線性匯編語言并對部分代碼進行匯編層的優化。
2.4 實驗結果
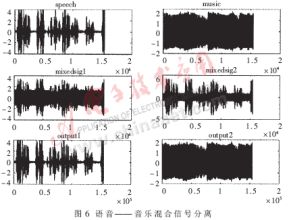
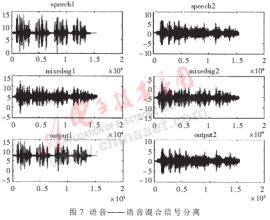
采用兩組混合語音來測試語音凈化系統,即單獨錄制兩個純凈的信號源,圖1所示模型用MATLAB混合(忽略噪聲),通過凈化系統得到兩組分離信號并與原始語音進行比對。x1(t)和x2(t)即為兩個麥克風的輸入信號。使用以下兩組聲音信號作為測試信號,第一組為語音和音樂信號,第二組為兩個語音信號,都是16kHz采樣16bit單聲道文件,長度均為7s。圖6與圖7分別為上述兩組混合語音的分離結果,從中可以看出分離效果非常令人滿意,達到了帶噪語音的凈化效果。
在實驗室環境引入語音凈化系統后,語音識別的速度雖然略有下降,但是識別語音的信噪比有顯著提高,在有不同信噪比的音樂和混響噪聲的背景中,識別率平均提高30%以上。
參考文獻
1 T. Nishikawa, H. Saruwatari, K.Shikano. Multistage ICA for of real acoustic convolutive mixture Proc.ICA2003,2003;(4):253~256
2 A.U.Batur,B.E.Flinchbaugh, M .H. Hayes. A dsp-based approach for the implementation of face recognition algorithms.ICASSP 2003, IEEE, 2003:253~256
3 Peiyu He, Piet.C.W.Sommen, Bin Yin. A real-time dsp blind signal separation experimental system based on new simplified mixing model. Proc of EUROCON’2001.Bratislava,Slovak Republic. 2001;(7):467~470
4 Chin.Heungsuk, J.Kim,ect. Realization of Speech Recognition using DSP(Digital Signal Processor). ISIE 2001, Pusan, KOREA,2001:508~512