
文獻標識碼: A
文章編號: 0258-7998(2014)01-0060-04
目前,諸多網(wǎng)絡流量識別技術[1]是根據(jù)數(shù)據(jù)包的IP地址、端口和載荷對網(wǎng)絡流量進行判斷,但隨著應用層協(xié)議種類在不斷增加,網(wǎng)絡流量逐漸龐大,加之網(wǎng)絡代理、端口的動態(tài)變化策略和協(xié)議加密等技術的采用[2],使得網(wǎng)絡管理愈加困難。如P2P通信通常采用隨機端口[3],迅雷的數(shù)據(jù)傳輸復用在HTTP業(yè)務之上等,而且這些數(shù)據(jù)所占比重越來越大。因此,有效地保障網(wǎng)絡安全,保證網(wǎng)絡資源的合理管理就顯得尤為重要。而傳統(tǒng)的識別方式已不能有效地識別。從目前來看,各種應用層協(xié)議識別算法的研究已經(jīng)取得了一些成果,但是還不足以解決當前所存在的問題。如將支持向量機方法應用于P2P流的識別領域[4],基于行為特征加權(quán)的P2P流識別方法研究[5],采用機器學習方法實現(xiàn)網(wǎng)絡協(xié)議識別[6]等。這些方法基本上都引入了數(shù)理統(tǒng)計的思想,在一定程度上解決了傳統(tǒng)端口和特征識別對加密協(xié)議難以識別的問題,但是效率仍然是制約其實際應用的關鍵因素。針對以上問題,在分析現(xiàn)有協(xié)議識別方法的基礎上,結(jié)合用戶對網(wǎng)絡應用識別準確性、高效性和擴展性的要求,提出了立體化的網(wǎng)絡應用層協(xié)議識別。
1 現(xiàn)有協(xié)議識別方法與存在問題
傳統(tǒng)的協(xié)議識別方法主要有基于端口的識別和基于負載的識別兩種[7]。隨著Internet數(shù)據(jù)流量的不斷增大、屬性的不斷變化,基于行為分析的協(xié)議識別算法也成為學者們研究的熱點。就目前來看,不管是從最簡單的端口識別到最繁雜的負載識別,還是最新的協(xié)議行為分析,都存在各自的不足,無法滿足實際應用對協(xié)議分析的要求。
(1)基于端口的識別。根據(jù)分析數(shù)據(jù)包的端口號來識別協(xié)議[8]。這種算法最大的優(yōu)點是效率高、能夠準確識別標準協(xié)議,但是現(xiàn)有的很多協(xié)議使用的端口均是非知名端口、并處于動態(tài)變化中,因此基于端口的協(xié)議識別也就逐漸失去效力。
(2)基于載荷的協(xié)議識別。通過對數(shù)據(jù)包內(nèi)容進行深度分析和檢測,掃描協(xié)議特征,對數(shù)據(jù)流進行分類。典型的開源包如IPP2P和OPENDPI等,都是根據(jù)協(xié)議的載荷特征進行分類。基于載荷的算法仍然屬于一元判別方法,從理論上講,只要有足夠的工作量,該算法即可以準確識別所有的非加密協(xié)議,但隨著協(xié)議不斷更新和加密協(xié)議的應用,這種方法工作量大,并且不能識別加密協(xié)議和大多數(shù)P2P協(xié)議。
(3)基于行為分析的識別算法[9]。利用協(xié)議規(guī)范的不同所造成的行為特征的差異區(qū)分協(xié)議。目前這種算法還在研究當中,但是從目前來看,準確性在70%~90%之間,而且效率較低,經(jīng)常出現(xiàn)延時和丟包等現(xiàn)象。
2 立體化協(xié)議識別系統(tǒng)設計
為了彌補單一采用上述方法的缺陷和協(xié)議特征庫更新難的問題,在基于Linux內(nèi)核的環(huán)境下,秉承模塊化的設計思想,結(jié)合上網(wǎng)行為管理系統(tǒng),通過不斷實踐與測試,采用樹形分類結(jié)構(gòu),加入表驅(qū)動的查找方法,改進DPI的統(tǒng)計識別算法和借鑒Linux驅(qū)動的加載模式,力求提高協(xié)議識別的準確性、高效性和可維護性。
2.1 系統(tǒng)識別方案
立體化的協(xié)議識別系統(tǒng)主要借鑒了樹形分類思想,從上至下,由標準簡單協(xié)議到繁雜協(xié)議逐層分類識別。其識別流程為:數(shù)據(jù)流首先進入數(shù)據(jù)包緩存,將五元組信息按照設定好的數(shù)據(jù)格式存儲并做相應的處理;然后進入到協(xié)議識別分析器進行協(xié)議匹配,最終輸出結(jié)果。
立體化協(xié)議識別系統(tǒng)主要包括初級層、中級層、高級層。在初級層主要是根據(jù)數(shù)據(jù)包的五元組進行分流,統(tǒng)計數(shù)據(jù)包的多元信息,方便快速識別;中級層以端口和首字節(jié)[10](載荷的第一位)的協(xié)議鏈為切入,協(xié)議特征庫為依托,實現(xiàn)基于端口和載荷的協(xié)議識別,主要針對RFC標準協(xié)議和部分P2P協(xié)議,承擔了70%左右數(shù)據(jù)包的協(xié)議識別;高級層主要是基于SVM機器學習的協(xié)議行為分析識別,實現(xiàn)對加密協(xié)議和P2P協(xié)議的自主學習識別。這部分一般占流量的30%左右,是識別的最后方法。立體化的協(xié)議識別流程如圖1所示。

2.2 改進的端口和載荷識別方法
由于單純采用端口和載荷識別有其局限性,屬于一元判別,因此這里使用了將端口和首字節(jié)作為協(xié)議鏈進行二元匹配,同時生成哈希表。根據(jù)數(shù)據(jù)包的端口和首字節(jié)將數(shù)據(jù)包分為有端口有首字節(jié)(優(yōu)先級最高)、有端口無首字節(jié)(優(yōu)先級次之)、無端口有首字節(jié)(優(yōu)先級其后)和無端口無首字節(jié)(優(yōu)先級最低)4種情況。當有新的協(xié)議鏈要注冊時,會按照優(yōu)先級狀態(tài)加入到協(xié)議鏈。如QQ的443端口0x00首字節(jié)的協(xié)議鏈:
{"tcp_qq_443_0x00",tcp_qq_443_0x00,exist_fiby,IP_TCP, most,0x00,443}
表明這是QQ的443端口,存在首字節(jié)0x00,屬于TCP協(xié)議,優(yōu)先級最高,掛載在443端口下。在協(xié)議鏈內(nèi)部,結(jié)合協(xié)議特征庫通過字符串、特征比對的方式進行進一步識別。如上述協(xié)議鏈的內(nèi)部特征:
if((*(payload+1)==0xb0)||(*(payload+2)==0x2c)||
(*(payload+0)==0x2c))
{
return PRO_QQ;
}
當數(shù)據(jù)包通過時,首先通過表驅(qū)動對應到具體的端口首字節(jié)協(xié)議鏈,然后依據(jù)協(xié)議特征庫比對,進一步準確識別。這樣不僅解決了單純采用端口和載荷識別一元信息單一的問題,而且提高了效率和識別的準確性。與此同時,系統(tǒng)已經(jīng)收集了100多種協(xié)議特征,工作量浩大。為了以后維護升級方便,根據(jù)每一個具體協(xié)議特征,將其獨立為C文件,組成一個協(xié)議特征庫。具體實現(xiàn)如下:借鑒Linux驅(qū)動模塊的加載方式,將每一種應用層協(xié)議以模塊的形式定義,當需要注冊使用時,通過包含進其頭文件,加入注冊函數(shù),動態(tài)加載后即完成新協(xié)議的注冊。通過采用這種方式,可以方便快捷地更改或添加協(xié)議特征庫,從而實現(xiàn)協(xié)議庫的升級,解決了協(xié)議載荷特征維護繁雜的問題,大大提高了系統(tǒng)的可維護性。
2.3 高級層識別方法
由于基于行為的識別方法具有機器學習的能力,是一個多維空間的統(tǒng)計判別方法,如何選擇盡可能少的屬性特征值是影響算法的重要因素[11]。目前針對P2P協(xié)議和加密協(xié)議,主要借助于支持向量機、神經(jīng)網(wǎng)絡和統(tǒng)計的方法,適合于粗粒度分類。
高級層識別方法算法的主要思想是:利用SVM的分類算法,統(tǒng)計在單位時間t內(nèi),相同IP通信的連接數(shù)M,高端口通信率H,發(fā)送包方差Q,流量占有率V,持續(xù)時間T這5個屬性分別作為二分類訓練,用于P2P和非P2P的分類;將雙向連接率B、等長度數(shù)據(jù)包率S作為精確P2P訓練屬性,最終實現(xiàn)對數(shù)據(jù)包的準確分類。
2.3.1 屬性選取
通過包屬性來區(qū)分包類別,需要選取各個數(shù)據(jù)包中差別較大的特征。在實際網(wǎng)絡環(huán)境中,隨著帶寬的不同及網(wǎng)絡設備的差異,所提取的特征屬性之間相互關聯(lián)。因此,從易于分析、差異較大的角度考慮,選取了9種屬性特征。具體特征如表1所示。

2.3.2 SVM的機器識別實現(xiàn)思路
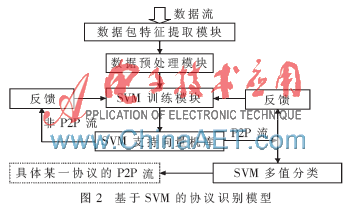
一對多SVM分類原理簡單,容易實現(xiàn),其基本思想為:k(k>2)類SVM分類,將類1視為一類,其余k-1類作為另一類,將k類分類問題轉(zhuǎn)化成二分類問題[12]。協(xié)議識別問題本質(zhì)是一個分類問題,協(xié)議識別模型是建立在通過大量已知流的屬性數(shù)據(jù)得到的。一個具有良好性能的支持向量機的關鍵在于模型的建立、核函數(shù)的選擇以及一些參數(shù)的選定。SVM的協(xié)議識別模型如圖2所示,數(shù)據(jù)包特征提取模塊主要負責從數(shù)據(jù)包緩存中獲取數(shù)據(jù),統(tǒng)計數(shù)據(jù)包特征值;數(shù)據(jù)包預處理模塊負責過濾掉雜包、緩存并轉(zhuǎn)換成SVM能夠執(zhí)行的標準格式;SVM訓練模塊完成數(shù)據(jù)的特征訓練。SVM支持向量機庫主要采用了臺灣林智仁教授的LibSVM庫,該軟件屬于開源的包,支持多種語言。基于SVM的反饋學習主要是通過設定一個識別的預設值,當識別率低于這一值時,將其放入反饋表中。總體而言,RBF核函數(shù)是一個普遍使用的核函數(shù),能夠適用于所有分布樣本。在參數(shù)選擇方面使用了python語言、gunplot以及LibSVM提供的tools交叉驗證選擇最優(yōu)的c和g。
3 實驗數(shù)據(jù)
3.1 實驗數(shù)據(jù)收集
為了驗證本文方法的實驗效果,分別在不同網(wǎng)絡環(huán)境下收集網(wǎng)絡數(shù)據(jù)包。圖3所示是實驗網(wǎng)絡拓撲圖。為了保證采集數(shù)據(jù)包的純凈性,每次在IP地址為192.168.1.161的機子上只運行一款軟件,通過Wireshark網(wǎng)絡封包分析軟件抓取各協(xié)議的數(shù)據(jù)包保存。

3.2 準確性與延時分析
3.2.1 應用準確性分析
通過上述數(shù)據(jù)收集,對常見的幾種P2P與非P2P協(xié)議包進行了測試。其中,包總數(shù)指經(jīng)過Wireshark過濾后純凈包的總數(shù)據(jù)包個數(shù);識別數(shù)指經(jīng)過協(xié)議分析后,能夠返回正確識別結(jié)果包個數(shù)。表2為協(xié)議識別系統(tǒng)對一些協(xié)議包的分析結(jié)果統(tǒng)計。通過分析發(fā)現(xiàn),對于標準協(xié)議識別率高于流媒體和P2P下載,這主要是因為機器學習分類方式是一種粗粒度分類方法,容易受到網(wǎng)絡環(huán)境的影響。

3.2.2 網(wǎng)絡延時分析
實驗中,利用Linux下TC對數(shù)據(jù)包打標命令,對某一條數(shù)據(jù)包打標,同時返回其經(jīng)過協(xié)議模塊一(端口載荷識別)和模塊二(機器學習識別)的標簽;然后計算其經(jīng)過系統(tǒng)分析后所花費的時間,得出每一協(xié)議延時量的平均值并統(tǒng)計出分別經(jīng)過模塊一和模塊二的包總個數(shù)。系統(tǒng)延時如表3所示,其中,包總數(shù)指的是實驗中所分析數(shù)據(jù)包的總個數(shù),占有率指數(shù)據(jù)包分別經(jīng)過模塊一和模塊二包個數(shù)占統(tǒng)計包總個數(shù)比值。可以看出,由于標準協(xié)議只經(jīng)過初級層和中級層的分析,因此延時量相對較小;而需要進行機器學習方式識別的P2P和流媒體協(xié)議,其延時量比較大,這主要由于SVM不斷學習反饋導致。但進入高級層識別數(shù)據(jù)包相對較少,基本在容忍范圍之內(nèi)。

3.2.3 對比分析
為了驗證本文方法在識別率和效率兩方面的提高,實驗對一些常用協(xié)議分別采用端口識別法、載荷識別法、傳統(tǒng)統(tǒng)計識別法和本文方法進行測試對比。從準確性上進行比較,如圖4所示。可以看出,基于端口的識別正確率接近于0,基于載荷的識別對HTTP和QQ登錄識別較高,而對采用加密的迅雷和FTP較低,而本文所采用的方法都高于它們。從效率上比較,如圖5所示,在相同的網(wǎng)絡環(huán)境下,端口和載荷的識別消耗時間都不會很大,統(tǒng)計的方法延時較高,而本文的方法介于兩者之間,因此該識別方法是行之有效的。

應用層協(xié)議識別作為計算機網(wǎng)絡研究的一個熱點,但其又必須兼顧準確性、實時性和維護性的設計要求,系統(tǒng)在傳統(tǒng)的協(xié)議識別的基礎上,通過添加基于機器學習的行為特征分析提高P2P協(xié)議分析的準確性,并采用表驅(qū)動的方法盡可能地改善系統(tǒng)運行效率。通過借鑒Linux驅(qū)動的模塊加載方式,將端口和首字節(jié)作為整體自動掛載到協(xié)議鏈,將每一種應用層協(xié)議以協(xié)議鏈的形式完成加載,提高了特征庫的可維護性。總之,通過不斷的改進與完善,基于立體化的應用層協(xié)議識別系統(tǒng)已被成功應用。但就目前來看,單獨的協(xié)議分析作用是有限的,它必須配合于其他模塊才能更好地發(fā)揮作用。為了使協(xié)議分析應用范圍更廣、效率更高以及更加準確,下一步工作將會結(jié)合審計和流控,繼續(xù)改進對加密協(xié)議、非標準協(xié)議的識別。
參考文獻
[1] 陳偉,胡磊,楊龍.基于載荷特征的加密流量快速識別技術[J].計算機工程,2012,38(12):1-4.
[2] 徐莉,趙曦,趙群飛,等.利用統(tǒng)計特征的網(wǎng)絡應用協(xié)議識別方法[J].西安交通大學學報,2009,43(2):43-47.
[3] 魏永,周云峰,郭利超.OpenDPI報文識別分析[J].計算機工程,2011,37(S1):98-101.
[4] 盤善榮.基于SVM的P2P流量識別方法研究[D].湖南:長沙理工大學,2009.
[5] 崔燕,汪斌強,陳庶樵.基于行為特征加權(quán)的P2P流識別方法研究[J].計算機工程與設計,2009,30(20):4805-4807.
[6] WU Amei,Dong Huailin,Wu Qingfeng,et al.A survey of application-level protocol identification based on machine learning[C].Proceedings of the 2011 International Conference on Information Management,2011.
[7] 劉元勛,徐秋亮,云曉春.面向入侵檢測系統(tǒng)的通用應用層協(xié)議識別技術研究[J].山東大學學報(工學版),2007,37(1):65-69.
[8] 陳亮,龔儉,徐選.應用層協(xié)議識別算法綜述[J].計算機科學,2012,34(7):73-75.
[9] 王明麗,傅彥,高輝.基于行為特征的P2P協(xié)議識別[C]. 中國計算機網(wǎng)絡安全應急年會信息內(nèi)容安全分會,2008.
[10] 牟喬.準確高效的應用層協(xié)議分析識別方法[J].計算機工程與科學,2010,32(8):39-45.
[11] 陳佳.應用層協(xié)議快速識別的研究與實現(xiàn)[D].北京:北京郵電大學,2010.
[12] 李衛(wèi)星.基于SVM的機器學習識別P2P流的方法的研究與實現(xiàn)[D].北京:北京郵電大學,2010.