
摘 要: 設計了一款具有4級流水線結構的16位RISC嵌入式微處理器。針對轉移指令,未采用慣用的延遲轉移技術,而是通過在取指階段增加相應的硬件結構實現了無延遲轉移。采用內部前推技術解決了指令執行過程中的數據相關。同時通過設置相應的硬件堆棧實現了對中斷嵌套和調用嵌套的支持。整體系統結構采用Verilog HDL語言設計,指令系統較完善。在軟件平臺上的仿真驗證初步表明了本設計的正確性。
關鍵詞: 微處理器;流水線;精簡指令集;現場可編程門陣列;嵌入式系統
隨著微電子及EDA技術的高速發展,可編程邏輯器件的研發與應用也取得了長足的進步。其中,基于現場可編程門陣列(FPGA)的片上系統(System on Chip)在嵌入式系統中得到了廣泛的應用。與傳統的專用集成電路(ASIC)相比,其具有開發周期短、設計簡單靈活等特點。
本文描述了基于FPGA的16 bit嵌入式微處理器的結構設計。該處理器采用程序存儲器與數據存儲器分離的哈佛型結構,采用精簡指令集(RISC),指令面向寄存器操作,加快了運行速度,簡化了控制邏輯。
1 系統結構設計
該處理器執行指令時按照取指(IF)、譯碼(ID)、執行(EX)和結果保存(WR)4個階段依次進行。由于采用4級流水線結構,每個時鐘周期能完成一條指令的執行。
1.1 指令系統
該處理器采用RISC型指令,設置了數據傳送、算術邏輯運算和程序控制3大類共21條指令,指令格式固定,每條指令長度為32 bit。
1.2 硬件結構
該處理器共有4級流水線,因此可將硬件基本劃分為取指、譯碼、執行和結果保存4部分。
1.2.1 取指
取指部分結構如圖1所示。與參考文獻[1]中提及的處理器取指部分相比,其增加了PC選擇生成器G_PC,通過它實現了無延遲的程序轉移指令。
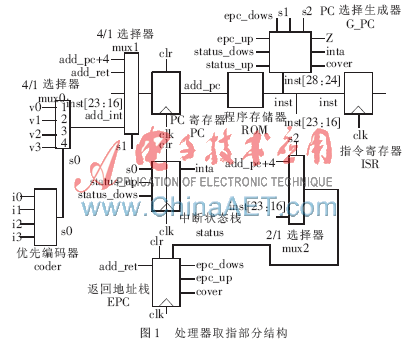
G_PC是本部分的核心,其部分Verilog HDL實現代碼如下:
……
input inta,z;//inta為中斷請求信號
//z為譯碼部分回送的信號,用于jz、jnz指令
input[4:0]p_op_code;//指令操作碼,即inst[28:24]
output status_up,status_down,epc_up,epc_down;
//對status和EPC進行出入棧控制
output s2;//對將要壓入EPC中的返回地址進行選擇
output cover;//控制EPC頂部單元數據是否被mux2送來的數據覆蓋
output[1:0]s1;//s1對下條指令的取指地址進行選擇
reg status_up,status_down,epc_up,epc_down,s2;
reg[1:0] s1;
always begin
case(p_op_code)
//根據指令的操作碼來產生信號的輸出
5′b00000:begin//此操作碼對應add ra,rb,rc指令
if(inta)begin
//如果有符合優先級條件的中斷請求則inta為1
status_down=1;
//控制status在下個時鐘沿將s0壓棧
status_up=0;
epc_down=1;
//控制EPC下個時鐘沿將相應的返回地址壓棧
epc_up=0;
s1=3;
//選擇中斷入口地址add_int作下條指令地址
s2=0;
//選擇當前指令地址加4作為返回地址壓入EPC
cover=0;//EPC頂部數據不被覆蓋
end
else begin//無符合優先級條件的中斷請求
status_down=0;
status_up=0;
epc_down=0;
epc_up=0;
s1=0;//下條指令地址為當前指令地址加4
s2=1′bx;//s2為無關信號,0或1均可
cover=0;
end
end
……
//其他指令類似,根據操作碼及是否有中斷請求來生成相應的輸出信號
endcase
end
優先編碼器coder則從硬件電路上實現了中斷源的優先級,即3號中斷優先級最高,然后依次遞減(3號中斷的優先級值為4,2號中斷的優先級值為3,1號中斷為2,0號中斷為1)。coder的輸出信號s0既代表了中斷的優先級,又起到了選擇中斷入口地址的作用。
取指部分的具體工作流程如下。
(1)假設此時指令地址add_pc在ROM中對應的指令inst為sub r0,r1,r2,此類語句不會使下一條指令地址發生轉移。同時假設沒有中斷信號產生,于是當下一個時鐘上升沿到達時,由G_PC生成的控制信號s1將add_pc+4選通送入PC寄存器中,即取出物理地址相鄰的下一條指令(加4是因為一條指令有32 bit,共4 B)。
假設add_pc在ROM中對應的指令inst為sub r0,r1,r2,且中斷狀態棧status頂部單元數據為0。此時有中斷信號0和中斷信號2產生,優先編碼器coder生成的s0為2號中斷的優先級3(大于status頂部數據0),于是中斷請求信號inta有效。當下一個時鐘上升沿到達時,G_PC生成的s2信號和epc_down信號將add_pc+4壓入返回地址棧EPC中,s0和由G_PC產生的信號s1將2號中斷的入口地址v2送入PC寄存器中(0號中斷被忽略掉),同時將s0的值3(即2號中斷的優先級)壓入中斷狀態棧status頂部。
(2)假設此時add_pc在ROM中對應的指令inst為絕對跳轉jump 100,即程序轉移到地址100處開始執行,且沒有中斷信號產生。則當下一個時鐘上升沿來臨時,由G_PC產生的s1等控制信號將inst[23:16](此時為100)送入PC寄存器中開始執行。
假設此時add_pc在ROM中對應的指令inst為絕對跳轉jump 100,但此時有中斷信號1產生(且假設此時status頂部值小于2),則inta為1。于是G_PC產生的控制信號將inst[23:16](即100)壓入EPC頂,將中斷1的優先級(即s0的值2)壓入status頂部,將中斷1的入口地址送入PC寄存器中,開始響應中斷。如果之后又產生優先級大于2的中斷,則將相關數據壓棧后響應中斷,若產生中斷的優先級小于或等于2,則被忽略不執行。
條件轉移jz、jnz與jump指令類似,只是當譯碼階段產生的Z信號為1時,jz跳轉,Z為0時jnz跳轉。通常比較指令comp后面緊跟條件轉移指令來實現程序轉移控制。
(3)假設此時add_pc在ROM中對應的指令inst為調用指令call 100,執行此條指令時忽略所有中斷請求信號,將add_pc+4壓入EPC中后,將inst[23:16](即100)送入PC寄存器中開始執行調用程序。
(4)假設此時add_pc在ROM中對應的指令inst為中斷返回指令int_ret,且沒有高優先級的中斷產生,則EPC頂部的數據add_ret送入PC寄存器中,同時,EPC和status中的頂部數據彈出,其余數據依次上移一位。
假設此時add_pc在ROM中對應的指令inst為中斷返回指令int_ret,但有優先級比status頂部單元數據高的中斷信號產生,則G_PC產生的cover信號有效,status頂部數據被新的中斷優先級值所覆蓋,EPC維持不變,同時響應新中斷。
(5)調用返回指令call_ret與中斷返回指令int_ret類似,不過執行時status中的數據不彈出。
1.2.2 譯碼
譯碼部分結構如圖2所示。
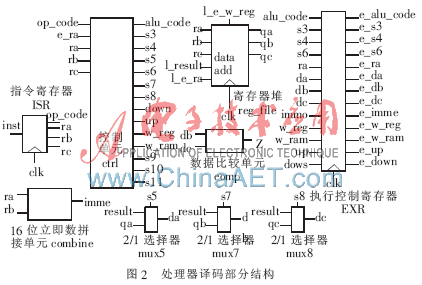
譯碼部分核心是控制單元ctrl。為了解決流水線的數據相關,采用了內部前推的方法,將執行部分產生的數據result回送至本部分。將比較單元comp產生的信號Z送至譯碼部分,使得條件跳轉指令(jz、jnz)在取指階段就能實現,從而實現無延遲跳轉。
本部分中的寄存器堆reg_file在時鐘下降沿且寫信號l_e_w_reg有效時執行寫數據操作(實現結果保存WR這一部分的功能)。ctrl產生的一部分控制信號通過執行控制寄存器EXR送至下一級使用。
1.2.3 執行
執行部分的結構如圖3所示。此部分核心是算術邏輯運算單元ALU,前面譯碼部分的ctrl產生的運算控制碼alu_code指定運算操作,運算結果c_out送入5/1選擇器mux6。關于mux6的其余4路數據對應的指令為:dout對應load ra,imme即將數據存儲器中指定地址單元M[imme]的數據送入ra號寄存器中;ds對應pop ra,即將數據堆棧stake棧頂的數據彈入ra號寄存器中;e_imme對應指令val ra,imme送立即數imme入ra號寄存器;e_db對應mov ra,rb即將rb號寄存器中的數據送入ra號寄存器中。

1.2.4 結果保存
這里的結果保存是針對目的地址為寄存器的指令,如算術邏輯運算指令、寄存器之間的數據傳輸指令等。工作流程即將圖3中RSR的l_e_ra、l_e_w_reg、l_result信號送入圖2中的reg_file。當時鐘下降沿到達且l_e_w_reg有效時,數據l_result被寫入l_e_ra號寄存器中。
2 仿真驗證
為了驗證該設計,利用Altera公司的Quartus II軟件進行仿真驗證。仿真時設計在取地址為32的指令時出現0號中斷,在取地址為52的指令時出現1號中斷。實際執行時,1號中斷嵌套在0號中斷之中。對應中斷的入口地址分別為48、68。仿真結果如圖4所示。

圖4中a0~a6分別顯示的是r0~r6號寄存器中的數據;v0、v1分別是0號中斷、1號中斷的入口地址;pc_num是處在取指階段的指令的地址;ints是中斷輸入信號,ints=1、ints=2分別表示外設請求1號中斷、外設請求2號中斷。從圖4中可以看出:
(1)幾乎每條處在取指階段的指令都要經過3個時鐘上升沿和一個時鐘下降沿后才執行完畢。這是因為指令取指完成后,還要經過譯碼、執行和結果保存3個階段,并且結果保存是在時鐘下降沿完成的。但由于是流水線結構,故等效于每一個時鐘執行一條指令。
(2)當取到地址為pc_num=32的指令時,中斷信號1產生,于是下條指令的取指地址為1號中斷入口地址48。執行1號中斷的子程序到52時,中斷信號2產生,于是響應2號中斷,下條指令地址為2號中斷入口地址68(2號中斷子程序就一條返回指令)。
(3)當執行地址為24的jump 0指令時,下條指令地址為0,實現了無延遲轉移。
綜上所述,經初步驗證,該設計能實現4級流水線結構,并具備中斷及其嵌套、無延遲轉移等功能。
本文設計了一種基于FPGA的16 bit嵌入式RISC微處理器。該處理器主要特點是通過增加硬件結構實現了對轉移指令的無延遲實現以及對中斷及調用指令的支持。在下一步工作中將優化結構設計,增加外圍設備,逐步構成一個高性能的單片系統。
參考文獻
[1] 李亞民.計算機原理與設計[M].北京:清華大學出版社,2011.
[2] 鄭緯民,湯志忠.計算機系統結構[M].北京:清華大學出版社,1998.
[3] 夏宇聞.Verilog數字系統設計教程[M].北京:北京航空航天大學出版社,2008.
[4] 于洋,肖鐵軍,丁偉.面向教學的16位CISC微處理器的設計[J].計算機工程與設計,2010,31(16):3584-3587.
[5] 張英武,袁國順.32位嵌入式RISC處理器的設計與實現[J].微電子學與計算機,2008,25(6):14-17.
[6] 曾舒婷,楊志家.高性能PLC專用指令集處理器設計與仿真[J].微電子學與計算機,2011,28(7):76-81.