
摘 要:介紹了重排序緩沖器實現思想與硬件結構,并提出了增加結果鎖存器和將重排序緩沖器由集中式改為分布式的設計,來降低重排序緩沖器設計復雜度的方案。
關鍵詞:重排序緩沖器;寄存器重命名;超標量;亂序執行;低復雜度
?
隨著科技的發展,人們對計算機處理速度的要求越來越高。為了提高微處理器的性能,人們提出了超標量流水線技術。超標量技術是指CPU在每個時鐘周期內可以完成一條以上指令的并行執行技術[1]。實現多指令并行執行的關鍵在于亂序執行。亂序執行是指不按照指令原始順序執行的技術。而實現指令亂序執行的關鍵是用到了寄存器重命名技術。寄存器重命名是用一個或者多個虛擬寄存器來代替真實的數據寄存器的硬件猜測方法。重排序緩沖器ROB(Reorder Buffer)是超標量處理器中基于寄存器重命名技術的一種實現結構,在MIPS R10000、Intel Pentium系列處理器和IBM Power系列處理器中得到了廣泛的應用。
本文在介紹重排序緩沖器原理和實現的基礎上,分析了重排序緩沖器的復雜度問題,即重排序緩沖器是一個占用大量寄存器資源并且有多個并行讀寫端口的復雜器件,耗費大量的功耗,容易出現不必要的延時。文中通過適當的改進方法,優化了重排序緩沖器的結構和性能。
1 超標量處理器中的寄存器重命名技術
1.1?超標量處理器
現今的超標量處理器都是通過一個時鐘周期內發射多條指令并且亂序執行這些指令來實現多指令并行技術的。
一般流水線技術的局限在于采用了按序發射指令的機制,指令必須按照原來的順序執行。即如果流水線中出現停頓,那么后續指令則無法前行。因此,若2條緊挨著的指令存在相關關系就會引起停頓。對于有多個功能部件的機器,會造成這些功能的閑置。亂序執行技術允許指令不按照原來的發射順序執行,哪條指令的操作數已經就緒,就可以提前執行。這樣可有效提高指令的執行效率。
1.2?寄存器重命名
亂序執行帶來的數據相關和控制相關的問題,實質上是由于使用了共同的寄存器資源保存了不同的變量值所引發的[2]。若采用更名的方法,用2個不同的寄存器來保存這2個變量,出現相關的2條指令就能并發執行,不會引起性能的損失。Tomasulo算法就是一種基于寄存器重命名的動態調度算法,并在超標量流水線中得到廣泛應用。
2?重排序緩沖器的分析及相關問題的提出
2.1?重排序緩沖器的原理
亂序執行會帶來數據沖突和控制沖突,數據沖突問題可以單純地采用保留站的調度技術予以解決,控制沖突的解決則要利用分支預測技術,而分支預測常常會帶來預測的失敗。如果僅僅允許亂序執行而不順序寫回的話,就會出現不可恢復的預測失敗。因此,在Tomasulo算法的基礎上,又采用了一種基于硬件的猜測技術—重排序緩沖器。
重排序緩沖器本質上也是一種寄存器重命名技術,重排序緩沖器提供了額外的寄存器,就像Tomasulo算法中的保留站擴展了寄存器堆一樣。重排序緩沖器在指令執行結束和指令提交之間保存指令的執行結果。因此,重排序緩沖器可以為指令提供源操作數,就像Tomasulo算法中的保留站一樣提供操作數[3]。在Tomasulo算法中,一旦一條指令寫入它的執行結果,任何后邊的指令都可以在寄存器堆中讀取該結果,在指令提交之前,數據寄存器不用得到更新,由重排序緩沖器在指令執行完畢和提交之前提供操作數。如圖1所示,重排序機制類似于一種旁路機制,這樣可將在重排序緩沖器中保存的某個指令的結果送到等待它的執行單元中,不用經過數據寄存器[4]。

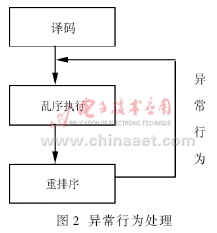
相比提供操作數,重排序緩沖器另一個最大的作用是保證指令有序提交和異常行為恢復執行[4]。提交階段必須按一開始程序的最初順序提交結果到指定的存儲單元。在指令譯碼之后、亂序發射之前,每條指令已經在重排序緩沖器中按序申請到存儲單元。當指令執行完畢,重排序緩沖器就可以保證最終結果順序提交。一旦出現中斷或異常行為,則廢除未提交的剩余所有執行結果,進入中斷處理或從正確的指令處重新開始執行。如圖2所示。
?
2.2?重排序緩沖器的硬件實現
重排序緩沖器是用于亂序執行后恢復指令原來順序的一種硬件結構,以達到指令結果順序提交的目的。可以把重排序緩沖器看作是一個包含頭指針和尾指針的堆棧FIFO[5]。每條指令進入流水線的時候,按照程序的最先順序都在重排序緩沖器中依次占據了一列條目,等指令執行完畢,按照先入先出的順序依次提交指令。當發生中斷或者異常行為時,也能恢復原來的執行順序。重排序緩沖器主要由下列幾個字段構成:
(1) 指令字段:記錄指令;
(2) 目標寄存器字段:記錄指令結果要寫入的數據寄存器的地址;
(3) 數值字段:記錄指令的最后結果,如果結果還沒有得出,則記錄得出該結果的指令在ROB中的地址;
(4) 完成字段:記錄指令是否執行完畢。
重排序緩沖器在超標量流水線中的實現如圖3所示。運算單元FU(Floating Unit)計算出結果后,將其寫到重排序緩沖器中。同時通過前置定向總線FB(Forwarding? Bus)送給發射隊列IQ(Instruction Queue)中正在等待該操作數的指令。重排序緩沖器中存儲的結果將在指令退休時送給相應的數據寄存器ARF(Architecture Register Files)中。在指令發射時,操作數的值按照具體情況,既可以從數據寄存器中獲得,也可以從重排序緩沖器中獲得,如果值還沒有計算出來,指令要在發射隊列中等待,直到前置定向總線將運算結果送到發射隊列指定的位置。
?

?
3?重排序緩沖器的復雜性和優化方案
3.1?重排序緩沖器的復雜性
這類的重排序緩沖器通常以允許多端口同時讀寫的寄存器堆的方式實現。在一個N指令發射的超標量流水線中重排序緩沖器至少需要2N個讀端口,以供N條指令可以在一個時鐘周期內讀取所需要的2N個操作數。至少需要N個寫端口,以供N條指令一個時鐘周期內將結果寫入重排序緩沖器中。
多端口寄存器堆的實現會加劇設計的復雜度,并且實際的端口數有時還會因為出現雙倍位寬的操作數而加倍。在通常情況下,可以采用雙重排序緩沖器并行存在的方式,以減少每個重排序緩沖器端口的數量。但是,雙倍位寬和單倍位寬的數據常常一起存在,倘若采用雙ROB的形式將不可避免的帶來極大地浪費。
另外,隨著端口數的增加,寄存器堆的面積也呈快速增長趨勢,這必將導致時序的延遲和功耗的增加。因此,合理地優化重排序緩沖器的結構設計日益成為人們關心的焦點。
3.2 重排序緩沖器結構的優化
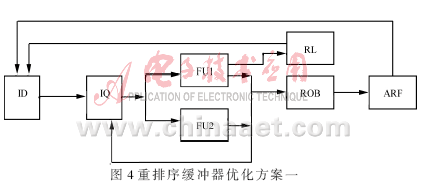
一個優化的方法是去除重排序緩沖器上原操作數讀端口用以簡化寄存器堆的設計。當指令的結果從運算單元送到重排序緩沖器中的同時,通過前置定向總線送到指令發射單元中等待該操作數的指令隊列。之后,該操作數提交給數據寄存器,指令分配單元無法再從重排序緩沖器中讀此操作數。當操作數需要第二次被提取時,而該操作數還沒有被提交給數據寄存器時,常常會因為無法讀重排序緩沖器中的值,出現延遲,造成流水線的阻塞。因此,可以參考計算機中緩存Cache的設計方法,如圖4所示,加一個存儲單元數遠少于重排序緩沖器的數據鎖存器RL(Retention Latches)以存儲指令結果,這樣執行結束的指令結果在寫入重排序緩沖器的同時也并行寫入了數據鎖存器。為了在增加數據鎖存器的基礎上而不增加設計的復雜度,數據鎖存器的存儲量應該盡可能的小,不妨采用LRU算法進行鎖存器內部數據的替換管理。LRU是廣泛應用于計算機緩存Cache中的一種數據替換算法,為了減少替換那些可能不久要用到的信息,需要記錄數據塊的使用次數來預測未來的使用情況[6]。這樣在指令被重排序緩沖器提交給數據寄存器之前,數據鎖存器可以有效解決操作數延遲獲得的問題。
?
另一個優化的方法,從Tomasulo算法的分布式保留站中得到啟發,將重排序緩沖器由集中式改為分布式,如圖5所示。這樣可以將一個多端口讀寫的重排序緩沖器簡化成多個單端口讀寫的重排序緩沖器。這種方法簡化了原來集中式寄存器堆多端口同時讀寫的復雜度,但也帶來了因為多個分散的重排序緩沖器中指令提交的排序問題。為此,可以在譯碼時給每一條指令加上標志位,指明該指令在程序中的順序,并且標注該指令發送給哪一個運算單元。這樣,在每個緩沖器提交指令或者預測失敗時,便能在多緩沖器間協調讀取指令或者結果。
?

3.3?性能分析
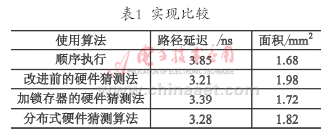
根據對各種模型的分析,列出表1中的順序執行、改進前的硬件猜測法以及改進后的硬件猜測法3種實現形式,采用Verilog HDL語言對結構進行描述,采用Synopsy公司的Design Compiler工具在0.18 μm的CMOS工藝下進行綜合和時序分析,得出性能的比較如表1所列。
?
從表1中可以看出,在普通的順序執行算法下,硬件路徑延遲較大,但是面積最小;改進前的硬件猜測算法路徑延遲最小,但是面積最大,帶來了設計上復雜度和功耗損失較大的問題;采用改進后的硬件猜測算法以后,雖然路徑延遲比改進前大,但是面積相對減少很多,并且路徑的延遲相比順序執行仍然減少了不少。因此,采用改進后的硬件猜測算法在減少面積的情況下得到了可觀的效果。
超標量處理器中的重排序緩沖器對于實現指令的亂序執行和順序提交起著重要的作用。隨著對指令并行度要求的不斷提高,重排序緩沖器的設計結構會越來越復雜。本文提出了幾點改進方法,通過減少單個緩沖器上讀端口的數目,有效地降低了重排序緩沖器的設計復雜度,這對將來的超標量處理器的設計有著深遠影響。
參考文獻
[1]?STEVEN W, NADER B. Modeled and measured instruction fetching performance for superscalar microprocessors. IEEE transaction on parallel and distributed, 1998,9(6).
[2]?JOHN P,MIKKO H L.現代處理器設計——超標量處理器基礎[M].北京:電子工業出版社,2004.
[3]?JOHN L H,DAVID A P.計算機系統結構——量化研究方法(第3版)[M].北京:電子工業出版社,2004.
[4]?鄧正宏,康慕寧,羅旻. 超標量微處理器的研究和應用[J].微電子學與計算機,2004,21(9):59-63.
[5]?TAREK M T, WILLS D S. An instruction throughput model of Superscalar Processors[J]. IEEE Transactions On Computers,2008,57(3).
[6]?李學干. 計算機系統結構[M]. 西安:西安交通大學出版社,2007.